Модель, рассчитывающая параметры пандемии является программной разработкой на базе математических алгоритмов с функционалом предикции, реализованной средствами машинного обучения.
Текущей версией системы используется ансамбль из 86 моделей (1 на страну и по 1 на регион) градиентного бустинга (gradient boosting) над временными рядами официальных чисел подтвержденных случаев COVID-19 в России.
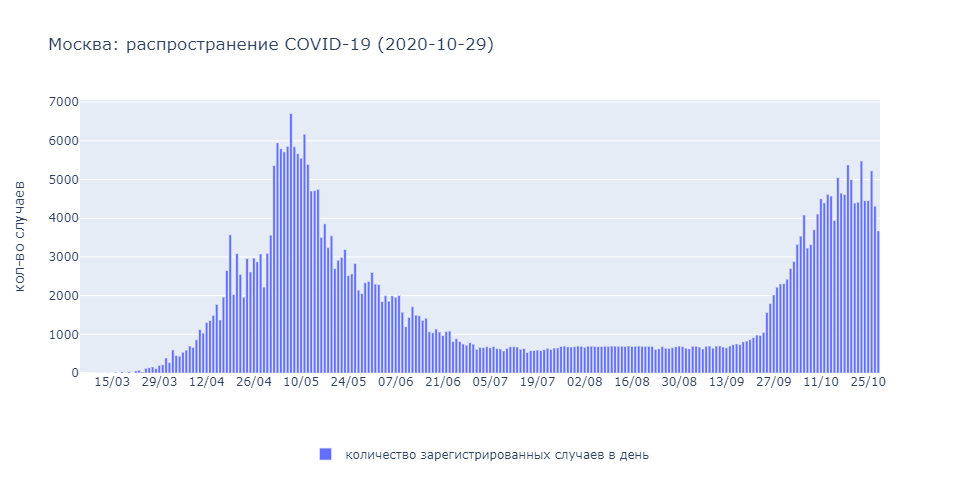
Временной ряд для одного из регионов представляет собой число подтвержденных (тестированием) случаев по дням. Это число далеко не идеально – большая часть инфицированных не проявляет симптомов, проявившие симптомы не всегда проходят тесты, тесты различаются в качестве, а количество положительных результатов может быть искажено в публикации. Тем не менее, даже с такими особенностями данных предиктивные модели над официальной статистикой заражений способны оценить если не точное число случаев, то хотя бы общую динамику развития пандемии.
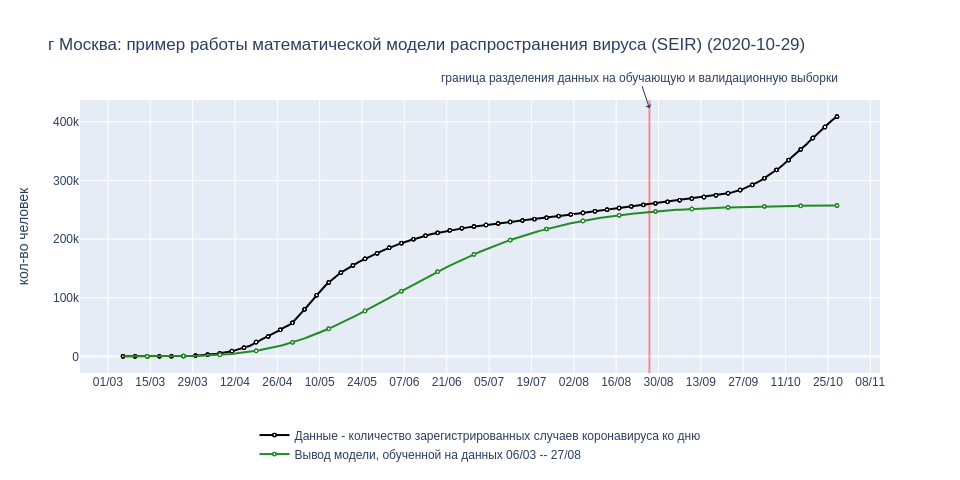
Работа классической модели SEIR
В эпидемиологии оценку темпов развития инфекционных заболеваний принято проводить с помощью «compartmental models» — математических моделей с интепретируемыми частями-«отделениями». Модель SEIR использует части Susceptible (подвержены), Exposed (инфицированы), Infectious (инфицированы), Recovered (выздоровели), с её помощью можно оценить не только число случаев в будущем, но и такие показатели инфекции, как период инкубации. К сожалению, большинство моделей подобного класса использует предположение, что карантинные меры не меняются с момента своего начала. Это приводит к тому, что на «настоящих» данных, которые отражают хаотичный характер принятия и отмены защитных мер, они слишком оптимистично предсказывают развитие событий, абсолютно не принимая во внимание возможность возникновения «второй волны».
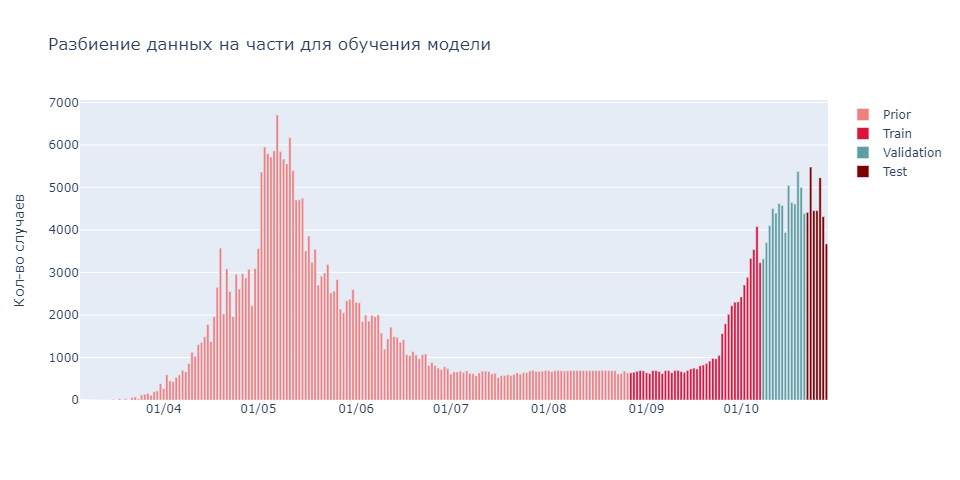
В «чистом виде» одна SEIR для наших задач не подходит, мы совмещаем её с другими средствами моделирования (машинного обучения). Для формирования задачи прогнозирования временных рядов данные необходимо разделить на части. В нашей системе таких частей 4 – prior, train, validation, test. На «prior» части происходит обучение «простых» моделей, SEIR и FB Prophet, выходы которых вместе с «train» частью подаются в основной ансамбль (ensemble) моделей (градиентного бустинга).
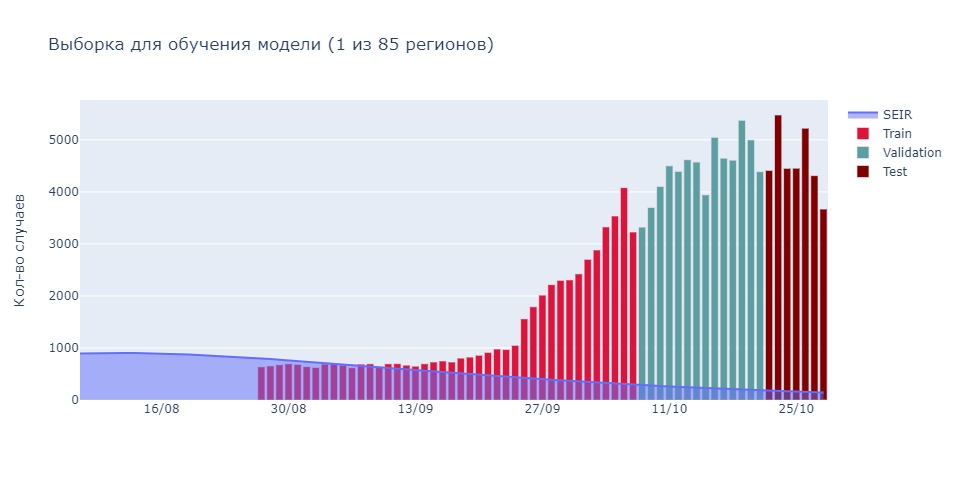
Train часть используется для обучения как общей основной модели (85 рядов), так и 85 региональных (по 1 ряду на модель). Validation часть используется для подбора коэффициентов: для каждого из регионов получены два вывода, X – основной модели, и Y – региональной; результат выводится в форме aX + bY, где a и b – лучшие коэффициенты в диапазоне [0.2, 0.8]. Test часть используется для контрольного сравнения.
Схема работы математической модели в системе
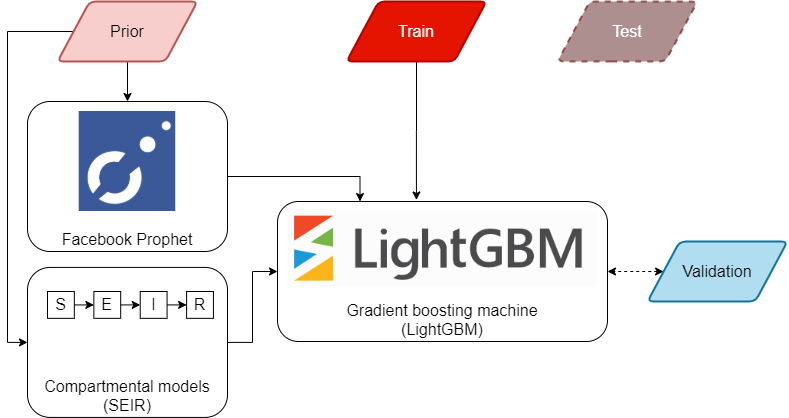
Схема работы (с некоторыми упрощениями) показывает, что происходит в процессе её работы:
1) Обновляются данные (python, requests, beautifulsoup4, pandas)
2) Обучаются модели prior-части – SEIR для случаев, FB Prophet для Rt. Для каждого региона обучается своя модель. (python, prophet, scipy)
3) Запускается обучение ансамбля моделей градиентного бустинга с подобранными ранее гиперпараметрами (python, lgbm)
4) С помощью завышения Rt во входных данных моделируются сценарии «второй волны».
5) Результаты выводятся в виде изображений графиков (python, plotly)
Преимущества работы системы
В результате получена система, которая обладает рядом преимуществ:
1) Ежедневное обновление.
2) Отсутствие «утечки» данных (data leakage).
3) Способность обработки различных сценариев развития ситуации.
4) Работа на большинстве регионов России.
Несмотря на то, что результаты моделирования могут не сильно различаться с реальностью, на отдельных промежутках времени часто невозможно предсказать изменение мер защиты от пандемии (например, ввод масочного режима).